Acapellify
Made by David O’Sullivan, Drew Kersnar, and Michael Ji
Email us at davidosullivan2021, drewkersnar2021, or michaelji2021 (@u.northwestern.edu)
Try out the algorithm here
Motivate the Problem
We wanted to create acapella versions of songs by using a clip of music and several clips of a person’s voice. The goal was not a particularly accurate recreation or important sound work or discovery, but rather something that could be entertaining, interesting, or artistically expressive. It allows anyone to create interesting “acapella” or sound art based on any music or sound of their choosing.
About Acapellify
The user uploads a “music” file. This can be whatever music (or other sound) that the result will based on. Then, the user can pick a “basis” file that should be in the form of a series of notes, which will be the sounds the result will be created with. In our testing, a chromatic scale (an octave split into half steps - 12 notes total) worked pretty well. We can then split the basis into individual notes and pitch shift them to actual notes. With some transformations and math, the music file will be recreated with just sounds from the basis file.
Development Process
Our project was not built off any dataset, but we did iteratively design the algorithm. We based the algorithm off work done with non-negative matrix factorization, which basically allowed us to divide (using a constrained least squares solver) our music (specifically, its magnitude spectrogram) and the set of basis vectors (in the frequency domain). This operation gave us a set of magnitudes which could be used with the original music to create an “acapellified” version. From here, we experimented with different inputs for both the music and basis, looking for what sounded accurate, entertaining, or interesting. For the basis vectors we tried voices, sinesweeps, individual sung notes, sung sweeps, and random crowd noises. In the end, we settled on the input being a scale: a set of 12 notes that makes an octave. To improve the quality of our sound, we experimented with many different techniques. Some, such as directly utilizing librosa’s NNMF were less succesful. The optimizations that we ultimately ended up implementing include: RMS normalization, pitch-shifting/auto-tuning, tukey windowing, note onset and end detection with RMS-thresholding, and mean-spectral-centroid outlier culling.
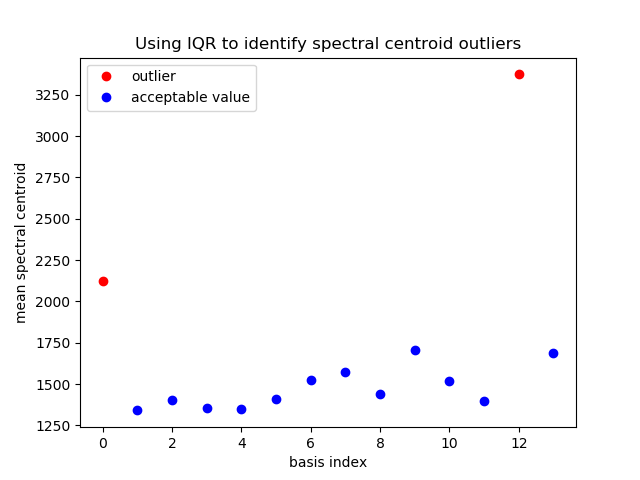
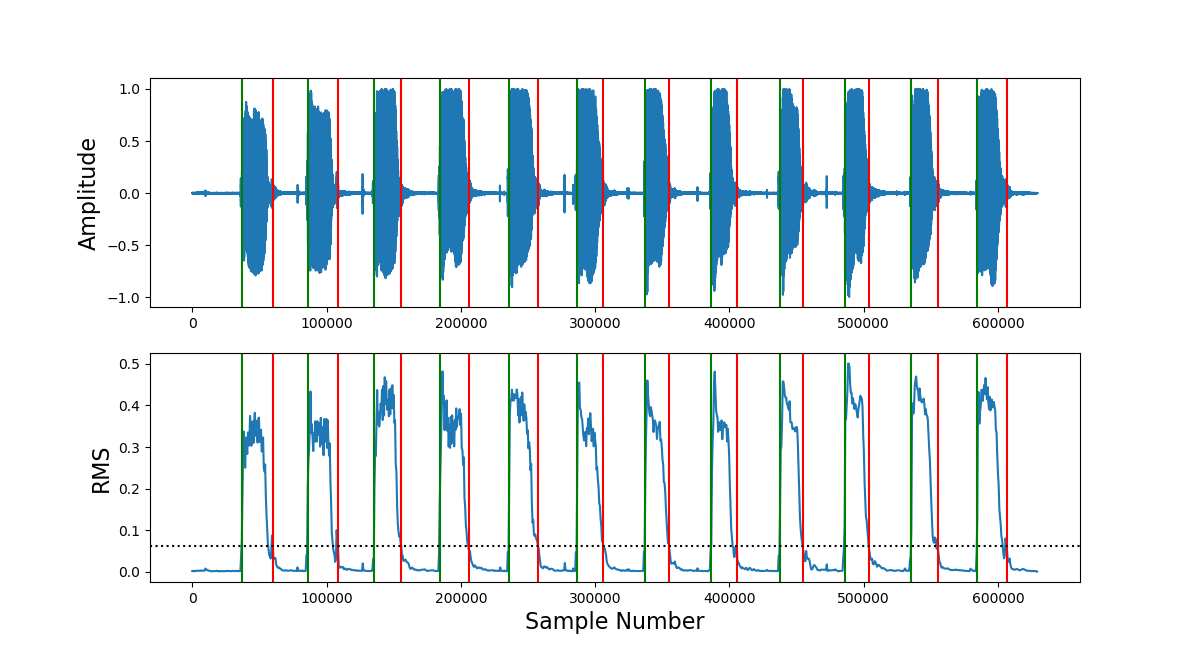
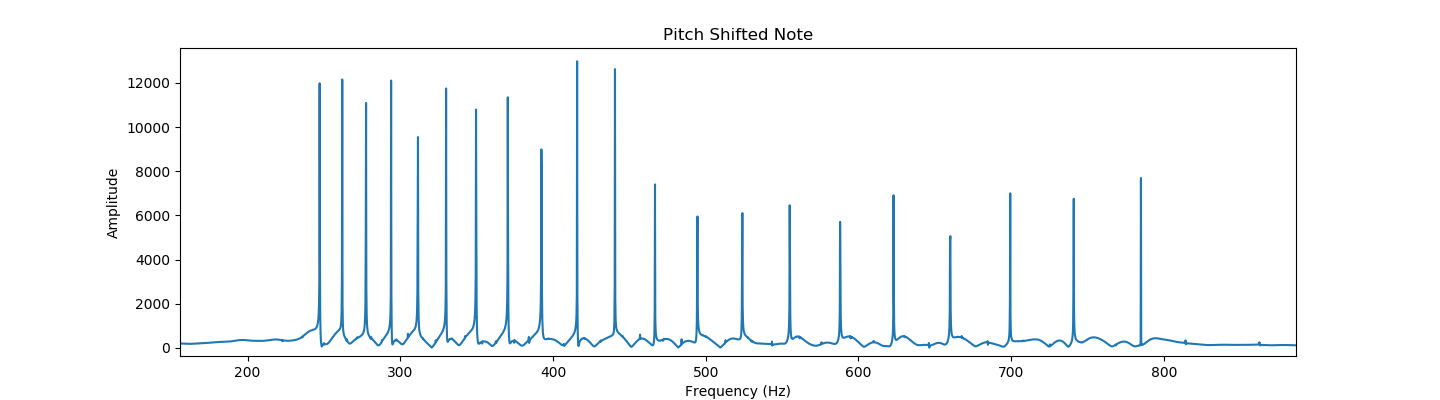
The algorithm produced some entertaining recreations, strange sounding sound-art, and even some relatively accurate songs. Our results were not exactly what we expected, but we believe we achieved our goal. Most songs are recognizable, and some recreations do sound close to a human voice. Listen below and try it out!
Examples
Developmental Tests
| Music file | Basis file | Result |
|---|---|---|
| Early Iteration: Pitch only goes up | ||
| Early Iteration: Lost Human Sound. (Only 1 of 9 basis included here) | ||
| No Window: Too clippy | ||
| Hann Window: Too Robotic | ||
| Tukey Window: Ideal, currently in use | ||
Final Algorithm Results
| Music file | Basis file | Result |
|---|---|---|
| One scale | ||
| Two scales | ||
A project for EECS 352, Machine Perception of Music and Audio at Northwestern University, taught by Professor Bryan Pardo